For me, the best way to learn anything is by creating and playing around with it. When I wanted to learn Reinforcement Learning (a subset of Machine Learning where the agent experiments with and learns from its own actions), I picked a game that I thought would pose a unique challenge. As it turns out this choice was fortuitous, as it has been called “A New Frontier for AI Research”. I implemented existing algorithms and applied it on my own as a way of creating a more intuitive understanding of why they work. This resulted in a framework for which various modifications could be mixed and matched to compare performance. To advance my knowledge in working with Tensorflow, I implemented GPU-accelerated ML by creating the nodes and logic in tensorflow rather than python.
This includes the following sections:
- The Environment, Hanabi
- Reinforcement Learning, Mixing and Matching
- GPU-acceleration using Keras and Tensorflow
- Unique Hanabi-Specific Model Enhancements
Hanabi
Hanabi is a deceivingly deep cooperative tile game that relies on asymmetric knowledge and limited communication to provide a challenge. The premise is simple: play your tiles in the correct order to create a fireworks show. The twist is that you can only see other people’s tiles, not your own, and you aren’t allowed to directly tell them what tiles they have. Creating an AI that can effectively play Hanabi poses a unique challenge for two reasons.
Theory of Mind (ToM)
ToM is the ability to reason about the mental state, such as intention or knowledge, of those around you. In order to win in Hanabi not only must you deduce why people are playing the way they are, you must also play in such a way as to create inferences in others when they do the same to you.
As an example, player one may hint to player three that a certain tile is a good idea to play. Player two sees this and knows it to be a lie, thus inferring that player one was actually trying to signal something else indirectly through the lie. This causes player two to gain pieces of knowledge and alter their playing style, thus also leading to more clues for others. This can lead to clues many layers deep that take almost the entire game to resolve.
If you want an idea of how complex strategies become, check out this page, in which players have attempted to write down what they know. Scroll halfway down, and you’ll start running into rules like “The Bad Touch Layered Finesse that Causes a Blind-Play of a Known Dupe (Dupe Bluffs / Bluff Dupes)”. Being good at Hanabi doesn’t rely so much on memorizing all of these rules, but rather logically inferring what the board state must have been in order for another person to make the (seemingly illogical) move.
Conventions
A group of players that play excellently in isolation may play poorly when mixed in with a different group that also plays excellently in isolation. This is due to a divergent set of conventions, in which players have a shared understanding of how to play. We already have seen a diverse range of both naturally emergent as well as artificially created conventions appear in the “wilds” of Hanabi pickup games.
Conventions are the language by which players attempt to communicate in the game, and I was both curious what language a machine would learn to use on its own as well as how we could encourage machines to learn existing languages. Creating an AI that is both effective as well as aligned with human intuitions are, at times, both conflicting and critically important goals.
AI Challenges
While current AI is exceptionally good at pattern-finding, researchers have struggled both to impart a understanding of the underlying mechanics as well as human-like values (or even human-understandable explanations) to their creations. In a world where we want to use AI alongside humans to augment and expand on our capabilities, both of these are crucial to adoption. Making advances in a controlled environment, such as playing a board-game, lead to generalizable advances in other fields.
Reinforcement Learning
Reinforcement Learning (RL) is a class of machine learning in which the computer makes moves, and updates its model based on the results. Q-learning is a common method in which the machine attempts to accurately assess the “value” of any given board state, and through it what moves must be made in order to maximize this value. This fits nicely into what ML is already good at: function estimation.
Through replaying previous experiences, a ML agent may begin to associate what board states and action combinations are valued at based on what board state it leads to. Initially, only the value of ending board states may be known – but the model works backwards, slowly refining its guesses over time. To aid in determining which actions were important, a “reward” is used, which defines the relative value of two states separated by the corresponding action.
Calculating the “correct” value of states to train the model on as well as the marginal value of each action is crucial to making RL work, and many advances have been made refining parts of the algorithm.
Mixing and Matching
There are several steps to reinforcement learning (choosing actions, creating experiences, calculating state values, etc.), and each step can be independently varied and still lead to a functional agent (usually).
A few other customizable parameters included in the framework are:
- The policy (which bandit algorithm is used for action selection during learning), along with policy parameters
- Double DQN version
- Dueling Q networks
- The model
- Optimizer
- Regularization
- Various hyperparameters such as batch size, memory size, max steps, discount, epoch size, etc.
This was all learned with the guidance of a textbook and using it to find relevant source material.
An Example: DoDQN
Double Deep Q-Networks (DoDQN) was a major leap forward in which snapshots of the model were taken, and state values were updated in comparison to the snapshot instead of the online model. This significantly stabilized the model, and lead to quicker and more reliable convergence.
There were actually two versions of DoDQN published in two papers (by the same author) several years apart. Since I was implementing each algorithm by hand and comparing scores achieved by each, I was able to compare each version to each other as well as in conjunction with other algorithmic adjustments. For me, learning what situations benefitted from one version or the other helped to understand why the improvement worked and gain more intuitive understanding.
Optimization: GPU-Acceleration
Accuracy is often constrained by compute available. Different methods and algorithms are a significant part of the puzzle, allowing for unnecessary steps to be skipped or a more optimal path found. No matter how clever your methods, optimization will always be helpful in extending how far your resources can go. After achieving a working framework and checking for bugs, I moved on to efficiency.
Significant advances were made in my framework after tracking where the program was spending its time and what specific step was causing the holdup. Oftentimes it was peculiarity in a package (did you know that creating a numpy array and converting it to a tensor is faster than creating a tensor directly?). As the experience replay was increasingly using a greater percentage of time, I knew the next step would have to be moving the calculation from the CPU to the GPU.
There were many roadblocks here. Much of the linear algebra hidden from the end user via keras and tensorflow was not able to be ignored any longer. While experience replay logic is easy to implement in python, parallelizing the work for transfer to GPU meant that creative matrix mathematics had to be used instead.
Overall, performing the experience replay in tensors and allowing tensorflow to perform the computation instead of python lead to the program running about twice as fast, with ~30,000 experiences trained per second, including playing the games and plotting the results.
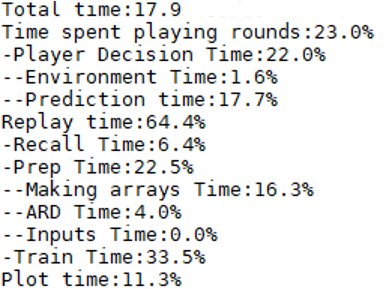
While I don’t have much to say about this section, it did provide an appreciation for what goes on behind the scenes and the heavy maths involved. My learning here was constrained to matrices and the workings of tensorflow and keras, but someday I hope to take it a step further and support distributed infrustructure with a scheduler and workers.
Hanabi Model Enchancements
Early attempts at customizing algorithms to Hanabi mostly revolved around trying different algorithms and hyperparameters. Alterations such as penalties for invalid moves or simply disallowing invalid moves was also experimented with. I wanted an agent that learned on its own not to play invalid moves, and so eventually settled only on a modification to the bandit algorithm such that it didn’t randomly select invalid moves.
Many changes that I implemented yielded failures or, more commonly, no change. For example one thing I tested was creating separate agents for each player or a single agent (with no memory). The main effect of having separate agents would be in the allocation of rewards: do all agents get a reward for playing a correct tile, or does only the agent that actually played the tile get a reward? I theorized that since it was a cooperative game, only rewarding the one agent would be nonoptimal and lead to selfish play.
Ultimately, I don’t feel like I made any worthwhile novel advances. I do feel that I have a much better grasp of the current state of RL, and hope to continue on this project, starting with the framework already developed, in the future. A summary of where things currently stand:
- Can play and train on 30,000 experiences per second (training 200k parameters) on a 1080ti
- Max score: average 16 points per game
- Everything done with 3 players in the standard game mode (without rainbow or variants)